Understanding Relay Data IDs
When I started using the Relay framework, I wasn't really sure what I was looking at inside the dev tools.
At first glance, it all may seem quite confusing, but after spending a few years working with Relay, it has started to make a lot more sense.
Firstly, it's important to note that Relay's store1 employs a normalized cache. Picture the store as a key-value data structure, like a Map; this is what is contained within the Relay store. As a user of the library, this is mostly abstracted away from you.
The Data ID is used as a key for a given value in the normalized cache. Consider the following type being a part of your schema:
type User {
id: ID!
name: String!
email: String!
}
Whenever you query or receive a payload containing a type with an id field, that value will be used as a key for the normalized cache in the store.
Consider an example type from above. Imagine your schema includes a query like this:
type Query {
getUser(id: ID!): User
}
Perhaps your Relay code is querying this data somewhere, and you are obtaining some fields using a fragment.
// user-panel.tsx
export function UserPanel() {
const data = useLazyLoadQuery<userPanelQuery>(
graphql`
query userPanelQuery($id: ID!) {
getUser(id: $id) {
...userPanelHeading_User
}
}
`,
{
id: "MTpVc2VyOjEyMw==",
}
);
return <UserPanelHeading dataRef={data.getUser} />;
}
// user-panel-heading.tsx
export function UserPanelHeading({ dataRef }: { dataRef: userPanelHeading_User$key }) {
const { id, name } = useFragment(graphql`
fragment userPanelHeading_User on User {
__typename
id
name
}
`, dataRef)
return <p key={id}><strong>Name: </strong>{name}</p>
}
And the response might look something like this:
{
"data": {
"getUser": {
"__typename": "User",
"id": "MTpVc2VyOjEyMw==",
"name": "Johnny Appleseed"
}
}
}
Upon receiving data, Relay recognizes the getUser field to return the User type. It then uses the key id with corresponding value of MTpVc2VyOjEyMw== and registers this in the store. Relay dev tools will display a key labeled getUser(id: "MTpVc2VyOjEyMw==").
This record, however, contains a __ref attribute that redirects to a separate stored record holding the MTpVc2VyOjEyMw== ID:

While the implications of this may seem negligible, its significance becomes apparent within a data-intensive application. Relay's approach emphasizes minimizing waterfall requests. This is evident in its adoption of data fragments, which are linked to React components. These fragments define data dependencies, however the actual data fetching can be triggered elsewhere within your component tree, optimally at the top, at the root level.
Let's' adjust our schema so the User implements the Node interface2. The Query now defines the node field:
interface Node {
id: ID!
}
type User implements Node {
id: ID!
name: String!
email: String!
}
type Query {
getUser(id: ID!): User
node(id: ID!): User
}
Consider the following scenario: you have a different UI, let's say a Card component which only needs user's email to render a gravatar. We'll use different fragment:
// user-card.tsx
export function UserCard() {
const data = useLazyLoadQuery<userCardQuery>(
graphql`
query userCardQuery($id: ID!) {
node(id: $id) {
__typename
... on User {
...userAvatar_User
}
}
}
`,
{
id: "MTpVc2VyOjEyMw==",
}
);
if (!data.node) {
return null;
}
if (data.node.__typename !== "User") {
return null;
}
return <UserAvatar dataRef={data.node} />;
}
// user-avatar.tsx
export function UserAvatar({ dataRef }: { dataRef: userAvatar_User$key }) {
const { email } = useFragment(graphql`
fragment userAvatar_User on User {
__typename
id
email
}
`, dataRef);
return <Gravatar email={email} />;
}
Calling the node query, we receive the following payload:
{
"data": {
"node": {
"__typename": "User",
"id": "MTpVc2VyOjEyMw==",
"email": "[email protected]"
}
}
}
Now the real fun part begins. Instead of storing this data under a new key, Relay recognizes that you've requested the same user data, but this time with additional fields. It retains the existing data but enhances it with the email field. Brilliant!
You can verify this by revisiting the Relay dev tools. You will now see a new key next to the existing getUser key, holding the value: node(id: "MTpVc2VyOjEyMw=="). However, it also has a reference (note the __ref property), which leads back to the same User record which now also includes the requested email field:

This significantly saves space in large applications, with the benefits becoming even more apparent when managing connections.
It's worth mentioning that it's quite common for some queries not to return a type with id. Let's introduce Version type, which characterizes a version of our application. This type doesn't include id, so it's unreachable via the node query.
type Version {
value: String!
}
type Query {
getUser(id: ID!): User
node(id: ID!): User
version: Version
}
We will query for that field via React component:
// version.tsx
export function Version() {
const data = useLazyLoadQuery<versionQuery>(
graphql`
query versionQuery {
version {
__typename
value
}
}
`,
{}
);
return <pre>{data.version?.value}</pre>
}
Upon calling version query, the returned payload from server has this shape:
{
"data": {
"version": {
"__typename": "Version",
"value": "1.0.0"
}
}
}
Inspecting the store via dev tools reveals that store now holds this data under key version, it points to this data via __ref property which has value client:root:version. How come?
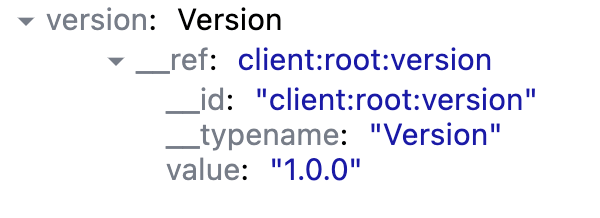
Since this query and its returned type do not contain an id field, Relay requires a unique key to store it in its normalized cache. Typically, this would be the value of the id. However, in this absence, the library generates its own unique key instead.
It's using client:root as its prefix. This prefix is pre-defined in the library, then it appends name of the query version which results in client:root:version.
Every piece of data can be referenced in the cache by a key. This key is known as Data ID. For types that contain an id field, they resolve to its value. For types that lack an id field, Relay generates one for you. This applies to our Version type as returned by our version query.
Relay can expose this Data ID value in queries using a special field __id. I call it special because this field, although not part of the schema, is added by Relay to every type for ease of use. This allows us to broaden our node query to retrieve the Data ID for the User type. In this case, the id value is what you will receive.
// user-card.tsx
export function UserCard() {
const data = useLazyLoadQuery<userCardQuery>(
graphql`
query userCardQuery($id: ID!) {
node(id: $id) {
__typename
... on User {
__id # << we added special Data ID field
...userAvatar_User
}
}
}
`,
{
id: "MTpVc2VyOjEyMw==",
}
);
if (!data.node) {
return null;
}
if (data.node.__typename !== "User") {
return null;
}
return (
<>
<pre>{data.node.__id}</pre>
<UserAvatar dataRef={data.node} />
</>
);
}
This will render MTpVc2VyOjEyMw== value inside <pre> tag. Does not look very useful at first sight but let's show an example with version query for completeness sake:
// version.tsx
export function Version() {
const data = useLazyLoadQuery<versionQuery>(
graphql`
query versionQuery {
version {
__id # << Data ID field
value
}
}
`,
{}
);
return (
<>
<pre>{data.version?.__id}</pre>
<pre>{data.version?.value}</pre>
</>
);
}
This code renders client:root:version inside <pre>{data.version?.__id}</pre> tag, which is located right above the 1.0.0 string (which is our value for the value field).
The usefulness of __id becomes increasingly apparent when your application performs advanced data manipulation within the Relay store. These manipulations often take place inside updater functions3, with an imperative approach.
It's typically straightforward to pass the id field to a mutation, but the __id field becomes far more crucial when dealing with connections. I will illustrate this concept by showing you how Data IDs are represented in connections.
We will enhance the schema and modify our User type. This type will now include a friends field that will return a new type, UserConnection. This field conforms to the Relay pagination specification, so we're also adding other types that should be included:
Note: I'm omitting some types we declared in previous steps for brevity.
# ...
type PageInfo {
hasNextPage: Boolean!
hasPreviousPage: Boolean!
endCursor: String
startCursor: String
}
type UserEdge {
cursor: String!
node: User
}
type UserConnection {
edges: [UserEdge]
pageInfo: PageInfo!
}
input FriendSearchInput {
name: String
}
type User {
id: ID!
name: String!
email: String!
friends(first: Int!, after: String, search: FriendSearchInput): UserConnection!
}
You can think of the friends field as a list of friends the given user has, with ability to filter this list with search argument. Let's augment UserCard component node query with new fragment. This fragment will belong to new component FriendList:
// user-card.tsx
export function UserCard() {
const [search, setSearch] = useState("");
const [debouncedSearch] = useDebounce(search, 500);
const data = useLazyLoadQuery<userCardQuery>(
graphql`
query userCardQuery($id: ID!, $name: String!) {
node(id: $id) {
__typename
... on User {
__id
...userAvatar_User
...friendList_User @arguments(name: $name, first: 10) # << new field
}
}
}
`,
{
id: "MTpVc2VyOjEyMw==",
name: debouncedSearch.trim().length > 0 ? debouncedSearch : "",
}
);
const handleInputChange = (event: React.ChangeEvent<HTMLInputElement>) => {
setSearch(event.target.value);
};
if (!data.node) {
return null;
}
if (data.node.__typename !== "User") {
return null;
}
return (
<>
{/* Used for debugging purposes, shows Data ID of User type */}
<pre>{data.node.__id}</pre>
<UserAvatar dataRef={data.node} />
<label>
Search:
<input type="text" value={search} onChange={handleInputChange} />
</label>
<FriendList dataRef={data.node} />
</>
);
}
// friend-list.tsx
export function FriendList({ dataRef }: { dataRef: friendList_User$key }) {
const { data, loadNext, hasNext } = usePaginationFragment(
graphql`
fragment friendList_User on User
@refetchable(queryName: "friendListPaginationQuery")
@argumentDefinitions(
first: { type: "Int", defaultValue: 10 }
cursor: { type: "String" }
name: { type: "String", defaultValue: "" }
) {
friends(first: $first, after: $cursor, search: { name: $name })
@connection(key: "user_friends", filters: ["search"]) {
__id # << adding for debugging purposes
edges {
node {
id
name
}
}
}
}
`,
dataRef,
);
if (!data.friends || !data.friends.edges) {
return null;
}
return (
<div>
{/* Used for debugging purposes - shows Data ID for the connection itself, I refer to this ID in following paragraphs */}
<pre>{data.friends.__id}</pre>
<ul>
{data.friends.edges.map((user) => (
<li key={user?.node?.id}>{user?.node?.name}</li>
))}
</ul>
<button onClick={() => loadNext(10)} disabled={!hasNext}>
Next
</button>
</div>
);
}
The first page received from server has this shape:
Note: I'm only including partial output to include first two edges.
{
"data": {
"node": {
"__typename": "User",
"id": "MTpVc2VyOjEyMw==",
"email": "[email protected]",
"friends": {
"edges": [
{
"node": {
"id": "MTpVc2VyOmZhZDkxZjIxLTVhYzEtNDY3ZC1hOWU3LTljMmQwOTQzYjY5Zg==",
"name": "Lana Maggio",
"__typename": "User"
},
"cursor": "MTpVc2VyOmZhZDkxZjIxLTVhYzEtNDY3ZC1hOWU3LTljMmQwOTQzYjY5Zg=="
},
{
"node": {
"id": "MTpVc2VyOjU2NDY2NWRhLWViNmYtNGM3My04MDQwLTk4MjUyNzU4ZDBjYw==",
"name": "Gertrude Rogahn",
"__typename": "User"
},
"cursor": "MTpVc2VyOjU2NDY2NWRhLWViNmYtNGM3My04MDQwLTk4MjUyNzU4ZDBjYw=="
},
// 8 other edges ...
],
"pageInfo": {
"endCursor": "MTpVc2VyOmMwYmIzYjY0LTJlZDgtNGRjNS04MTg0LWZhOGY1MjgxM2QxOA==",
"hasNextPage": true
}
}
}
}
}
There's one detail you might've missed in the code for the FriendList component's fragment definition. I've included the __id field to help us uncover how the connection is identified via its Data ID. The value of this ID is:
client:MTpVc2VyOjEyMw==:__user_friends_connection(search:{"name":""})
Let's break down how this Data ID is created with the following diagram:
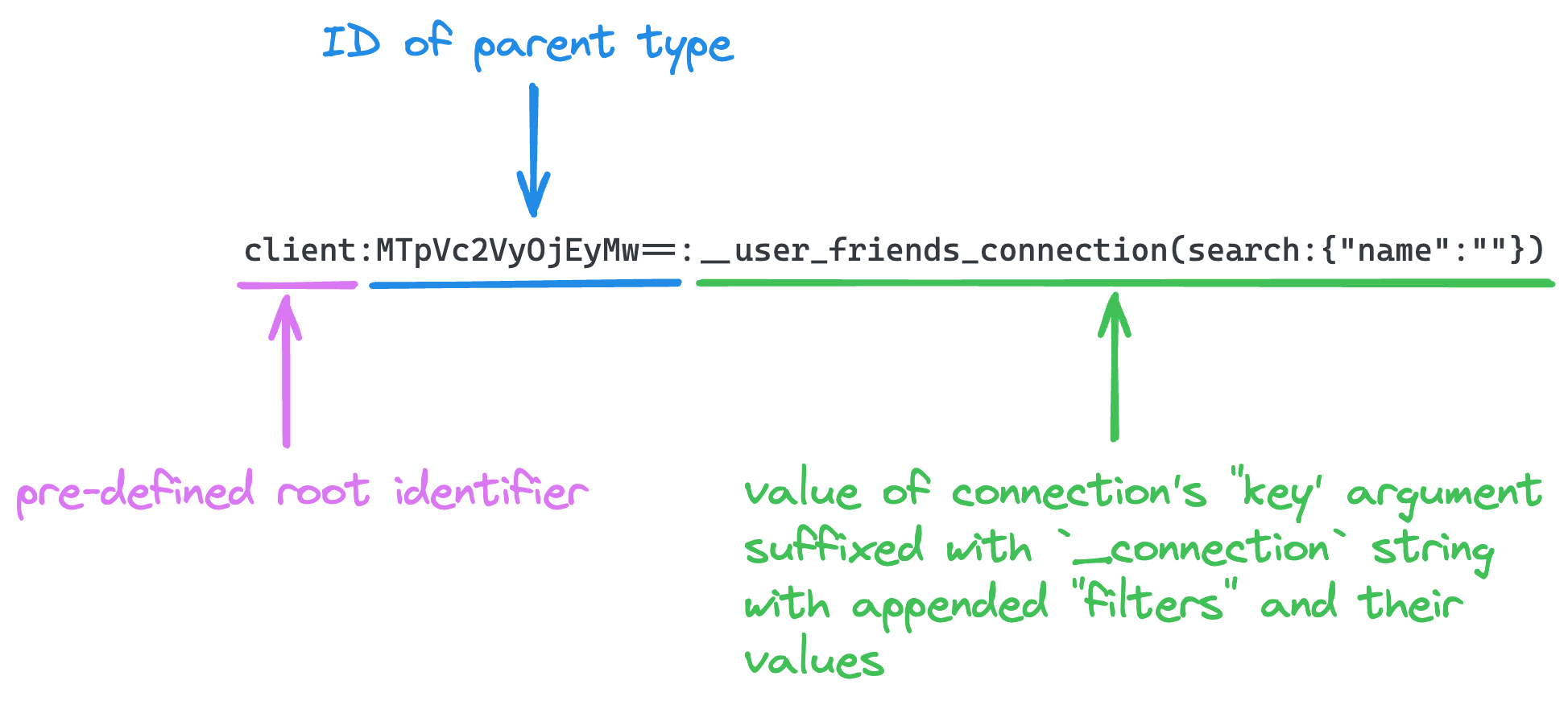
Why and how is this Data ID created? It appears similar to what we've previously observed with the version, getUser and node fields. In our schema, the UserConnection does not contain an id field. This means that Relay needs to generate the ID for us, which it accomplishes by concatenating several strings. The double colon : is used as a separator between these strings.
We've touched on the client string before; it's a pre-determined value from the Relay library used as the root prefix. Up next, the Data ID of its parent type is utilized - in our case, this would be equivalent to the id field of the User that we've queried with node query.
Finally, it uses the value of the key argument supplied to the @connection directive. We set it as user_friends in the friendList_User fragment. Interestingly, this key is prefixed with __. This final section of the Data ID also encompasses serialized arguments given to the connection, in this particular scenario search, which is an empty string right now. I'll delve into these elements shortly.
Let's look at Relay dev tools to understand how it represents this connection with only first page loaded:
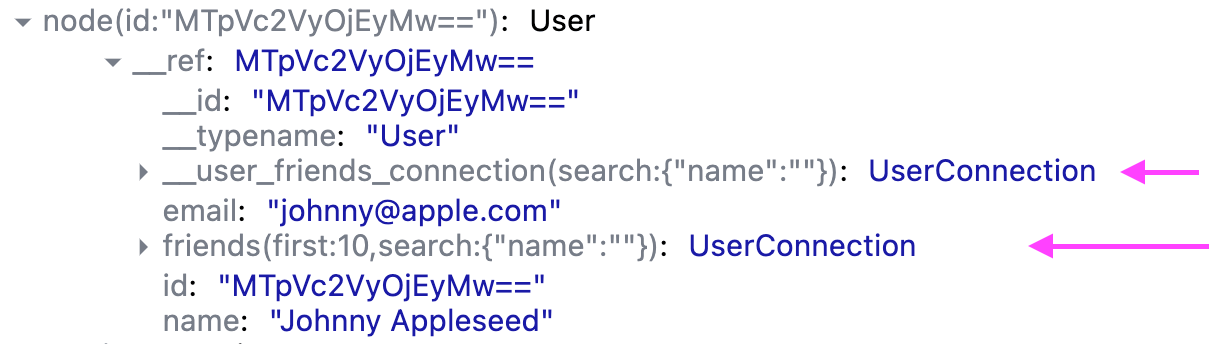
That's strange, it looks like there are two fields associated with our User record:
__user_friends_connection(search:{"name":""})friends(first: 10,search:{"name":""})
What’s going on? Here's how I see it: any field that begins with an underscore(s), such as the first one, is an internal field that is somehow special. The field __user_friends_connection(search:{"name":""}) matches the suffix of the connection's Data ID. Let's fetch another page using loadNext and observe what happens.
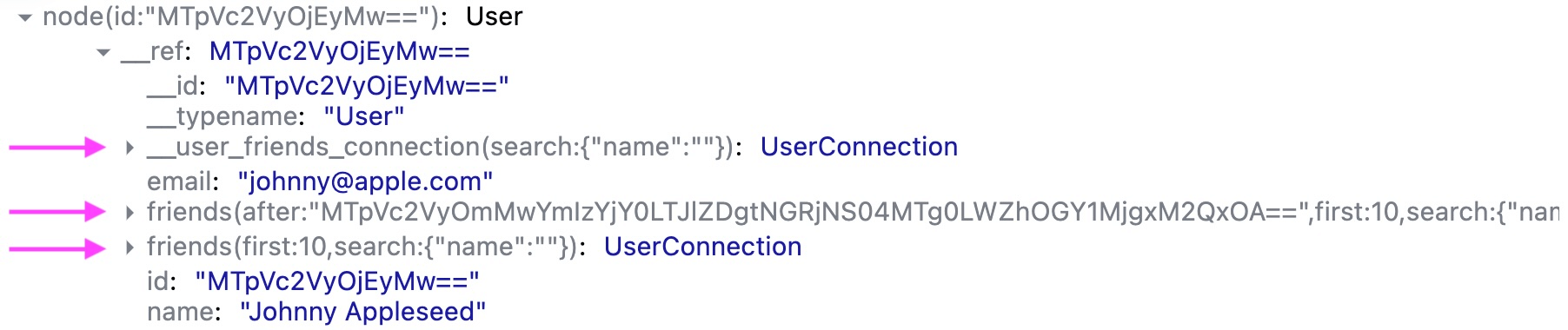
Now we have additional friends field in our User record:
__user_friends_connection(search:{"name":""})friends(first: 10,search:{"name":""})friends(after:"MTpVc2VyOmMwYmIzYjY0LTJlZDgtNGRjNS04MTg0LWZhOGY1MjgxM2QxOA==",first:10,search:{"name":""})
The third field signifies another page, since after is a cursor to get the next page and it's one of the connection arguments, it gets serialized as well.
The __id field of the connection itself that we're rendering in FriendList component like so:
<pre>{data.friends.__id}</pre>
Is still equal to previous value and has same Data ID: client:MTpVc2VyOjEyMw==:__user_friends_connection(search:{"name":""})
The way I interpret this is that the internal field __user_friends_connection(search:{"name":""}) is essentially read by the usePaginationFragment hook. This field amalgamates all the other pages (of the UserConnection types) so they can be shown as a single list in our user interface. It is capable of resolving those two fields (see #2 and #3 in the list above) on our User record and then treating them as one collective list. It uses the after argument to know that it needs to append it to the existing list. This process can be visualized by expanding the __user_friends_connection(search:{"name":""}) field in the development tools.

Upon inspecting this field, you'll notice that it contains all 20 edges. This means two pages, as each page consists of 10 edges. If you were to use loadNext(5), it would only append 5 records to this list. Much like the after argument, Relay is clever enough to understand that we still want to present all of this data as a single list in our UI.
Imagine our UI has input to search through the friend list. We've already fetched two pages without any search argument. Now we pass value "Tim" as a search term.
As a user you will expect that UI will clear our existing list and replace it with new one, containing only the filtered values. This time our Data ID rendered inside React as data.friend.__id has different value:
client:MTpVc2VyOjEyMw==:__user_friends_connection(search:{"name":"Tim"})
Our search argument to the connection gets serialized into its Data ID. The hook is now reading from different Data ID with its own internal field to which subsequent pages will be appended. In our case we only get 2 edges though:

If our search results had more than 10 edges and we'd fetch another page, new field friends(first:10,search:{"name":"Tim"},after:"cursor") would appear in the store, its internal field __user_friends_connection(search:{"name":"Tim"}) would be updated with these new edges.
This mechanism provides very quick user feedback. In case the user clears the input field for search term, our previously fetched pages will appear instantly as they're read from the cache - very smart and efficient!
The difference between __id field queried via fragment versus how Data IDs are represented in the dev tools were the main source of confusion for me. You can see that Relay internally serializes all connection arguments such as after, first but they are missing from __id field. This is explained in the documentation4:
[...] each of the values passed in as connection filters will be used to identify the connection in the Relay store. Note that this excludes pagination arguments, i.e. it excludes first, last, before, and after.
Our search field is part of __id field because we explicitly added it as filters argument to @connection directive in the FriendList component:
@connection(key: "user_friends", filters: ["search"])
This tells Relay to include it as part of the connection identity. For queries with connections that do not have any extra filtering, it is recommended to completely omit filters argument, the arguments such as first, after, before etc are implicit.
For example if in our case we would not want to include search in Data ID, we can set it up like this:
@connection(key: "user_friends", filters: [])
The __id field will now have value client:MTpVc2VyOjEyMw==:__user_friends_connection.
In some situations you might want to omit some argument to your connection field to keep the identity of the connection the same, regardless of the changed input. Relay will still create its internal fields like we've seen before but Relay hook will treat it as the same connection. It gets much more useful inside updater functions, where you can call store.get(__id) and be sure you'll get that specific connection.
Lastly, I need to mention that Relay exposes set of utility function ConnectionHandler.getConnection that can generate Data ID as well. It is imperative way which requires you to pass record containing the connection, it's key argument and any other arguments so in practice, it means passing all the values around in order to access them. I find querying for __id to be more convenient and easy to use.
The store is a data structure that contains queried, cached or payload data related to GraphQL operations performed via Relay hooks. It offers many methods to read and write to the store. You can find more in the official documentation(archive)